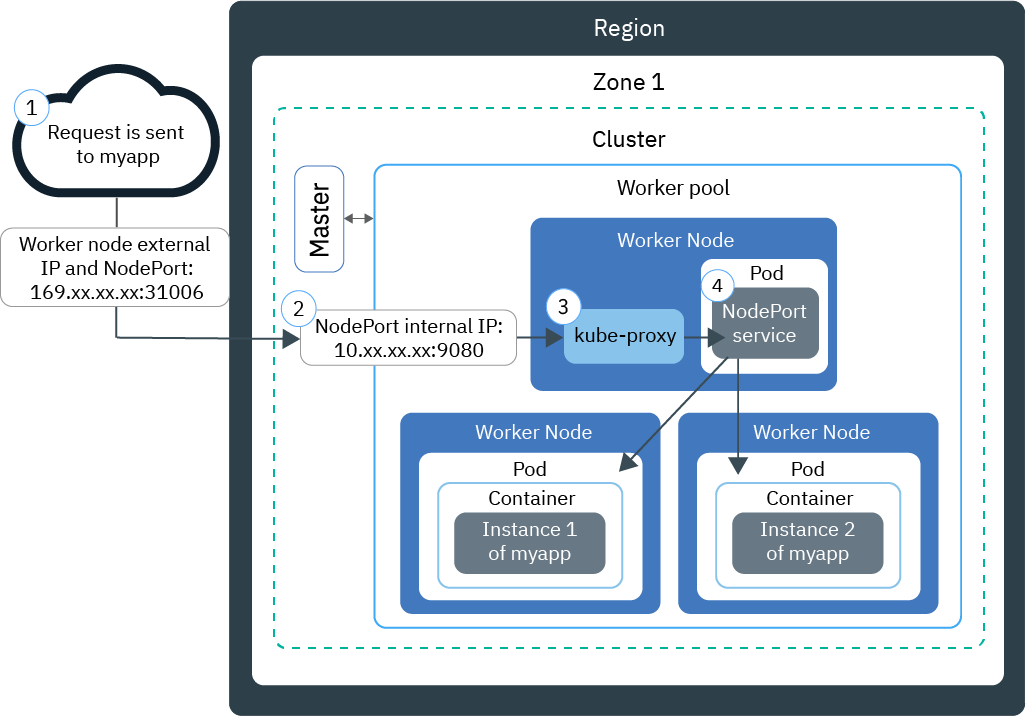
什么是流处理器,流处理器有什么用?A卡与N卡流处理器数量比较
中关村卖场中,一位装机技术员侃侃而谈:“ NVIDIA最新的GTX295显卡核心只有2*240个流处理器, ATI的HD5970显卡核心却有3200个流处理器,你要最高性能的显卡,当然要选HD5970显卡。”
AMD-ATI显卡(以下简称A卡)和NVIDIA(以下简称N卡)在流处理器数量上的巨大差异给许多读者造成巨大的困惑。其实,这个情况和不同厂商、相当于CPU的二级缓存数量存在差异情况类似,简单来说就是“不同架构的GPU,流处理器的作用不尽相同,不能直接比较数量。”深入的解释请看下文说明:
早在微软推出的DirectX 7当中就曾经提出过一个概念——T&L(中文名称是坐标转换和光源),它可以看做是流处理器的鼻祖,随着显卡核心芯片技术的发展,在DirectX 8中。由微软首次提出了Shader的概念。并且将Shader分为Vertex Shader(顶点着色器,又称VS单元)和Pixel Shader(像素着色器,又称PS单元)。
一副游戏画面是怎么显示的呢?其中,3D物体的几何形状、光亮和阴影的控制是由Vetex Shader来实现的,而Pixel Shader是对象素资料进行操作运算的指令程序。其中包括了像素的色彩、深度坐标等资料,在GeForce 8之前,Pixel Shader和 Vetex Shader这两个参数非常重要,这两个部分的多少完全决定了显卡的性能表现,N卡和A卡双方都为了提升Pixel Shader和Vetex Shader的数量而想尽一切办法。但是,在DirectX 10这一代显卡中,业界提出了一个新的概念——统一渲染架构,就是把原有的VS单元和PS单元统一起来,统称为Shader运算单元。这也就是我们所说的流处理器(Stream Processor)。因此,上述任务就由流处理器统一执行了,既然流处理器是来自于VS单元和PS单元的统一渲染架构。那么,流处理器的作用于VS单元+PS单元的合作用就是基本相同的。只是添加了全新的处理单元——Geometry Shader(几何渲染器,又称GS单元)。
同一架构的显卡,流处理器的个数自然是越多越好。相信读者也在各大网站了解到这样的信息——“同价位的产品中,N卡的流处理器数量要少于A卡”。比如本文开头的装机技术员提到ATI Radeon HD5890显卡比NVIDIA GeForce GTX275显卡的流处理器数量多,这是正确的。但是性能却是前者稍逊于后者.这是为什么呢,其实在“流处理器”的名称上A卡和N卡存在细微的差别,N卡的流处理器全称为Stream Processing,而A卡的流处理器全称为Stream Processing Units,一词之差却让两者的的性能差距有着天壤之别。而且因为A卡和N卡的GPU架构存在根本性的差异,所以流处理器的工作方式和用途也有所差异,故不能直接比较流处理器的数量。这就可以解决许多读者的疑问了 。A卡的GPU流处理器数量多很多但性能不一定就好。下面我们来分析A卡和N卡的GPU架构及流处理器的工作方式,看看有什么不同.
在DirectX 9时代末期,ATI意识到像素渣染的重要性,就通过1:3的架构提高了像素着色器的数量.到了DirectX 10时代,ATI还是通过这种方式来提高重要的像素渲染性能。从RV770的核心架构图中可以看出,现在在ATI的GPU中,流处理器(Scteam Processing)和流处理单元(Stream Processing Units)的比例就是1:5,也就是说ATI的每个“Stream Processing”都包含有5个“Stream Processing Units”。RV770的流处理器组群扩充至10组,因此数量也有了25倍的增长。达到160个(160×5=800个流处理单元).所以A卡所称的“流处理器”实际上一般是指流处理单元。
NVIDIA方面,GeForce GTX200核心架构分为四个层。最上面一层包括几何着色器(Geometry Shader)、顶点着色器(Vetex Shader)和像素着色器(Pixel Shader).中间一层包括了10组TPCs(计算处理器群集)。每组TPC里面又包含了3组SMs(流处理器组) ,每组SM里面就包含了8个流处理器单元或计算单元,这样一来,GeForce GTX 200显卡就一共包含了240个流处理器单元或计算单元.流处理器是直接将多媒体的图形数据流映射到流处理器上进行处理的,有可编程和不可编程两种。1995年公布的名为Cheops中的流处理器,是针对某一个特定的视频处理功能而设计的一种不可编程的流处理器。但为了得到一定的灵活性,系统中也包含一个通用的可编程处理器。
从1996年到2001年,MIT和Standford针对图像处理的应用,研制了名为Imagine 的可编程流处理器。Imagine流处理器没有采用cache,而是采用一个流寄存器文件SRF(Stream Register File),作为流(主)存储器与处理器寄存器之间的缓冲存储器,来解决存储器带宽问题的。流存储器与SRF之间的带宽是2GB/s,SRF与处理器寄存器之间的带宽是32GB/s, ALU簇(ALU Cluster)内寄存器与ALU之间的带宽是544GB/s,三种带宽的比例关系为1:16:272。
抗锯齿是3D特效中最重要的效果之一,它经过多年的发展,变为一个庞大的家庭,有必要独立开来说明一下。
作用:去除物体边缘的锯齿现象,广州话称之为“狗牙”,大家可以想像一下狗牙是如何的凹凸不平。
过程:我们在真实世界看到的物体,由无限的像素组成,不会看到有锯齿现象,而显示器没有足够多的点来表现图形,点与点之间的不连续就造成了锯齿。
抗锯齿通过采样算法,在像素与像素之间进行平均值计算,增加像素的数目,达到像素之间平滑过渡的效果。去掉锯齿后,还可以模拟高分辨率游戏的精致画面。它是目前最热门的特效,主要用于1600 * 1200以下的低分辨率。理论上来说,在17寸显示器上,1600 * 1200分辨率已经很难看到锯齿,无须使用抗锯齿算法。如此类推,在19寸显示器上,必须使用1920 x 1080分辨率,总之,越大的显示器,分辨率越高,才越不会看到抗锯齿1920 x 1200。由于RAMDAC(Random Access Memory Digital to Analog Converter,随机存储器数/模转换器)频率和显示器制造技术的限制,我们不可能永无止境地提升显示器和显卡的分辨率,抗锯齿技术变得很有必要了。
超级采样抗锯齿
最早期的全屏抗锯齿,方法简单直接。首先,图像创建到一个分离的缓冲区,缓冲区图像分辨率高于屏幕分辨率,假设是2*1(或2x),那么缓冲区场景的水平尺寸比屏幕分辨率高两倍,若是2*2(或4x)抗锯齿,缓冲区图像的水平和垂直均比显示图像大两倍。像素计算加倍之后,选取2个或4个邻近像素,此过程称为采样。把这些采样混合起来后,生成的最终像素,拥有邻近像素的特征,那么像素与像素之间的过渡色彩,就变得更为近似,整个图像的色彩过渡趋于平滑。再把最终像素输出到帧缓冲,作为一幅图像存储起来,然后发到显示器,显示出一帧画面。每帧都进行抗锯齿处理,游戏过程中的所有画面都变得带有抗锯齿效果了。
游戏卡曼奇四中采用的4X抗锯齿算法,Commanche 4 4xs
边缘超级采样抗锯齿
超级采样效果很好,但效率极低,严重影响显卡性能。新的4x抗锯齿方法,只把抗锯齿应用于物体边缘,避免占用过大的缓冲区。工作过程比超级采样稍为复杂,几何引擎生成多边形后,光栅单元会进行描色工作,同时检查当前的纹理,看看它是否需要用2×2采样的方式填充到多边形边缘。如果不是,GPU只计算一种色彩,在中间插入纹理像素,然后用单色填充这个块。这些就是非边缘像素,无须进行抗锯齿处理。
总结:
在进入统一渲染架构时代后,提高Shade运行频率与效率是NVIDIA主导的设计思路,而AMD则维持庞大的流处理器数量。两种思路各有优劣。
1、N的优势和A的劣势
N卡的GPU中每个流处理器都具有完整的ALU(算术逻辑单元)功能,在发出一条操作指令时每个流处理器都能充分工作.而A卡的GPU中每个流处理器的5个流处理单元都是固定的,不能拆开重组,如果在处理纯4D指令的时候,每个流处理器只能处理一条4D指令,有一个流处理器单元闲置,但却无法加入其他组合来共同工作.
简单地说,一个指令任务派发下来的时候,N卡的GPU是需要1个“人”独立工作即可完成。而A卡的GPU则需要5个“人”。结组工作才能完成ATI的人数虽然多,但这5个“人”中有可能会有4个“人”闲置,因为这4个“人”不具有独立完整的ALU功能,不能执行函数运算,浮点运算和Multipy运算。
2、N的劣势和A的优势
ATI的设计也有其显著的特点——浮点运算能力强大。也就是说如果单纯比拼显示核心在浮点运算上的能力的话,可能ATI则要强一些,在目前GPGPU(通用图形处理器)项目应用比较多的科学计算方面,理论上能适应GPU和CPU融台的趋势。
3、结论
因此,开篇提到的,因为N卡的一个流处理器等于五个A卡的流处理单元,也即HD5970的3200个流处理单元相当于640(3200/5)个流处理器。