记一次k8s云平台边缘节点到容器不通问题排查
熟悉 k8s 的同学都会知道,Kubernetes 的网络定义了一套容器网络 API 接口 CNI(Container Network Interface),这样我们就可以使用任意的第三方网络插件,给我们提供了多样化的网络解决方案。每个解决方案,都有自己的实现方式,相应的,当出现一些网络问题时,也需要我们有能力去分析定位和解决问题。
先介绍一下我们大概的业务背景:
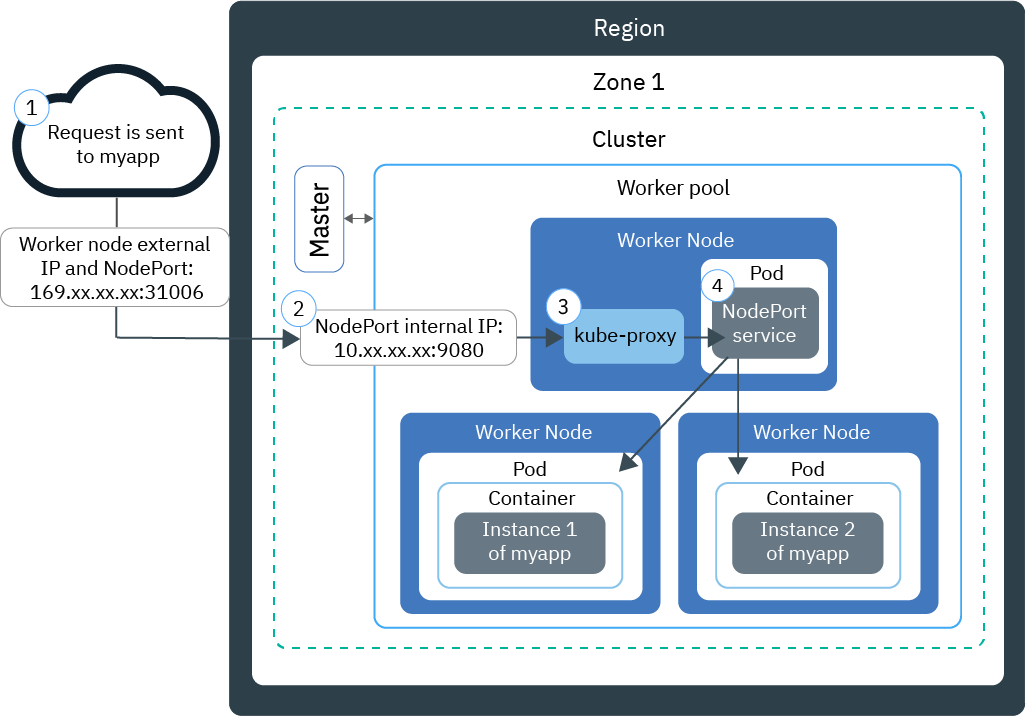
我们的服务部署在 360 搜索自建的 k8s 云平台上,有 4 个主力集群,业务对外提供 service 的方式为 基于 iptables 模式的 kube-proxy, 通过 nodePort 的方式,指定多台 external IP (也称为边缘节点),前边挂载 lvs 的形式。
从网上找了个图,比较类似了,只是把左边的 Worker node 多部署几台,前边通过 lvs 实现负载均衡即可。
在某次业务问题排查中,定位到通过某个集群的 lvs vip 访问业务时,有一定的几率产生超时,于是就有了此次的踩坑之旅。
先用一个脚本查看访问 vip 的超时情况,发现是链接阶段超时:
TIME_OUT_FMT='\ntime_namelookup: %{time_namelookup}s\n time_connect: %{time_connect}s\n time_appconnect: %{time_appconnect}s\n time_pretransfer: %{time_pretransfer}s\n time_redirect: %{time_redirect}s\n time_starttransfer: %{time_starttransfer}s\n'
for n in {1..20} ;
do
echo $n;
# 这里 url 用业务的 vip 地址
curl -w "$TIME_OUT_FMT" -o /dev/null -s 'https://fukun.org'
done
根据之前另外一个集群的经验,怀疑是边缘节点容量不足导致的,但是查看边缘节点的网卡丢包情况,并未出现异常,不过还是先对此集群的边缘节点进行了扩容,但扩容之后并没有好转。
此时由于对业务任然在产生影响,为了止损,所以快速的通过 ingress-nginx 部署了一个直接对外的支持 HTTPS 的服务,切换到 ingress 后,业务检测正常,此时是下午6、7点钟,已经不是流量高峰,当到第二天流量早高峰时,由于 ingress 服务之前主要是内部业务之间调用,并未启用 HTTPS,虽然单机的 QPS 6800+ 相比之前的 6000+ 并没有增加多少,但是 nginx 活跃连接数却从之前的单机 700 飙升到了单机 8000, 此时 ingress 服务虽然还能用,但对延迟已经有影响了,对于内部大部分 100ms 级别的请求来说,超时的影响已经比较严重了。所以此时只好先快速的把流量切到其他机房,避免 ingress 影响扩大。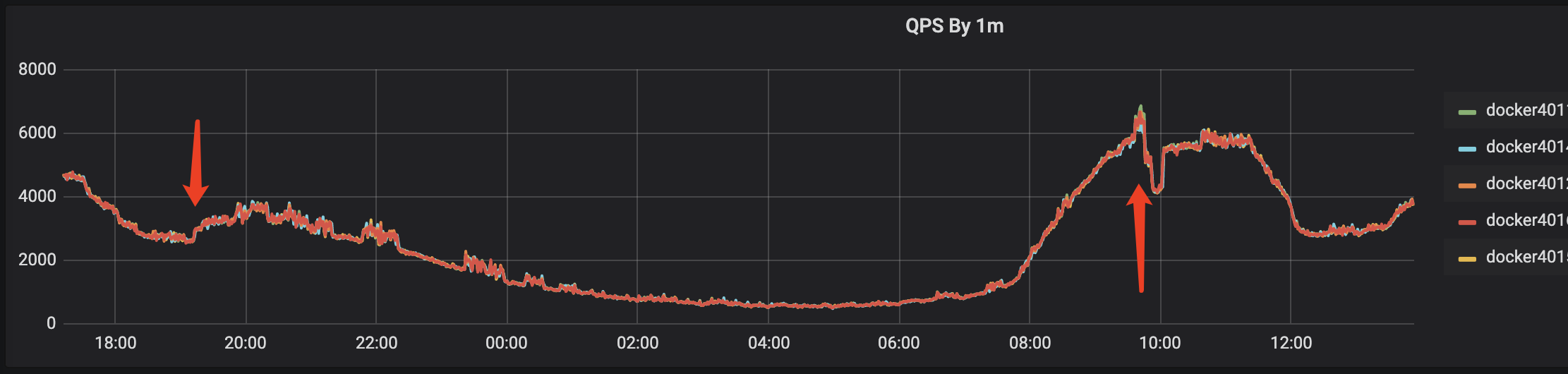
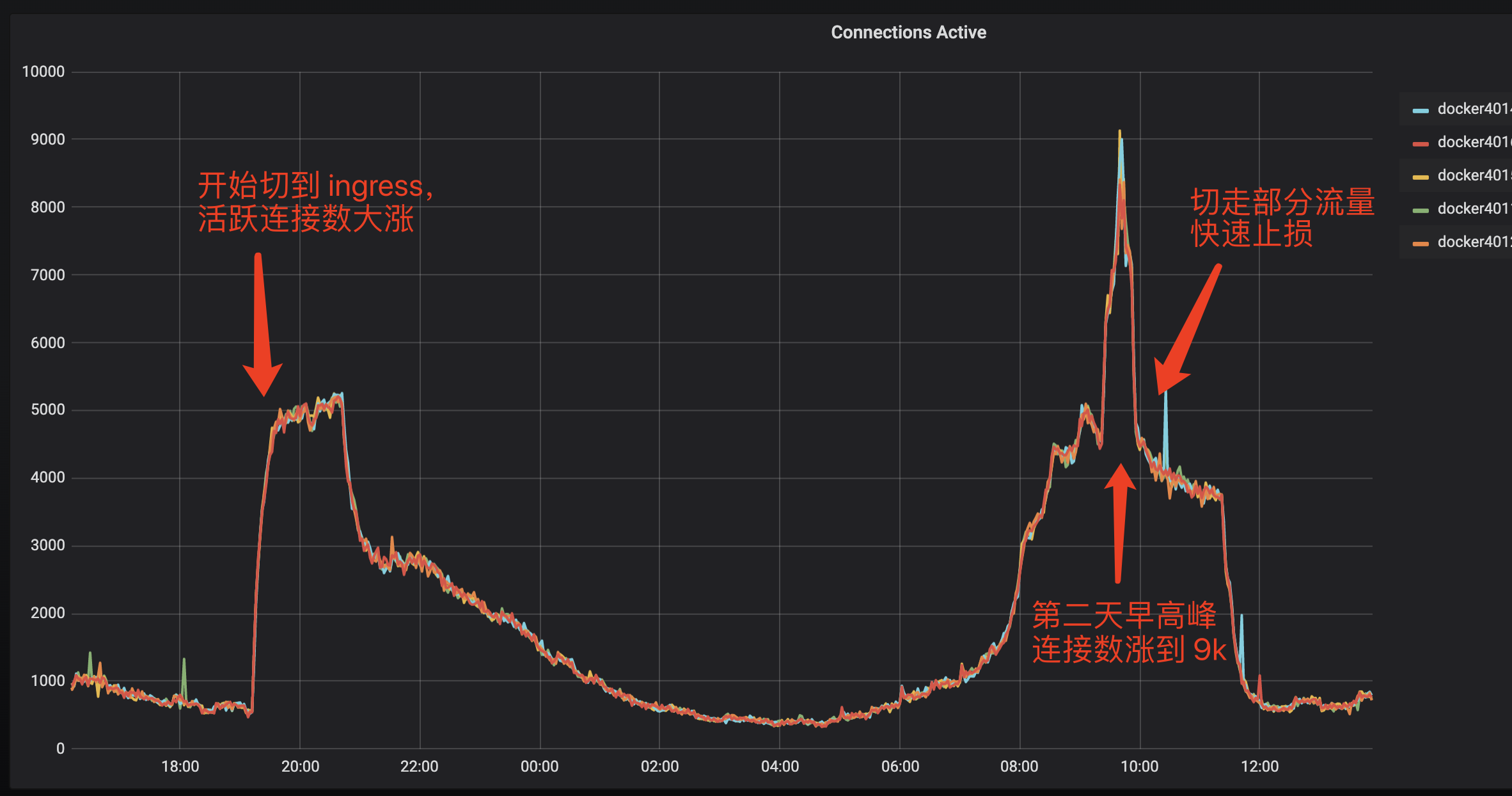
继续排查边缘节点的问题,通过对边缘节点 vip 的每个 节点进行检查,发现只有在部分节点上有超时出现,所以先将可能会产生超时的节点从 vip 下线,这样线上业务就恢复正常了。
IPS="10.10.10.1 10.10.10.2 10.10.10.3 10.10.10.4"
TIME_OUT_FMT='\ntime_namelookup: %{time_namelookup}s\n time_connect: %{time_connect}s\n time_appconnect: %{time_appconnect}s\n time_pretransfer: %{time_pretransfer}s\n time_redirect: %{time_redirect}s\n time_starttransfer: %{time_starttransfer}s\n'
for ip in $IPS
do
echo $ip
for n in {1..20} ;
do
echo $n;
# 这里 url 用业务的 vip 地址
curl -w "$TIME_OUT_FMT" -o /dev/null -s "https://${ip}" -H 'host:fukun.org'
done
done
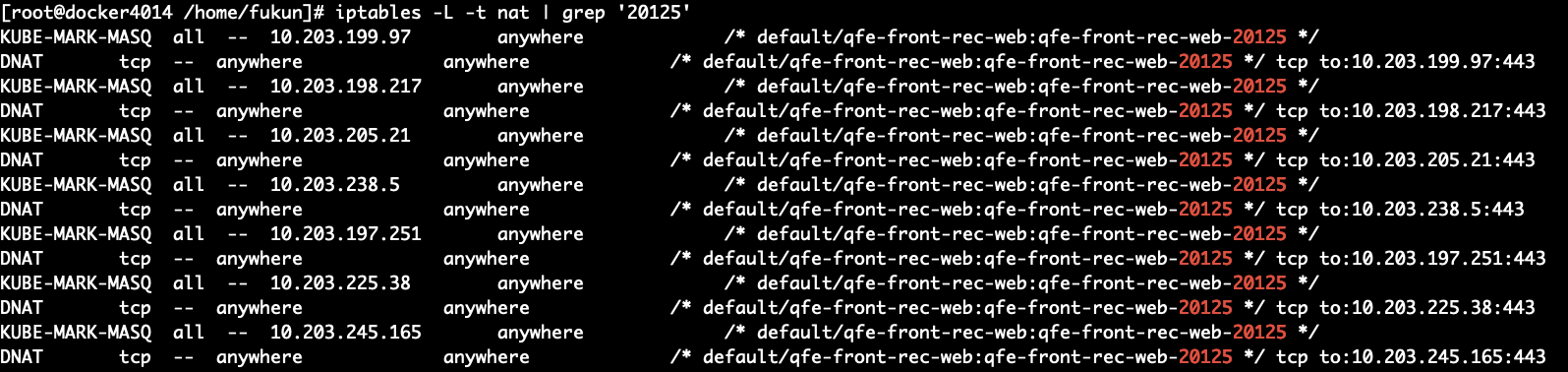
继续排查问题,目前的链路情况是:外部用户通过 lvs 到达 边缘节点(External IP),访问对应的 port,根据边缘节点机器上由 kube-proxy 维护的 iptables,随机将请求转发给对应的 pod,由于定位到了是单个边缘节点的问题,这里转发失败可能的原因,根据之前的经验,猜测是由于 kube-proxy 服务停掉或不稳定 导致的 iptables 没有及时更新,业务 pod 滚动后,旧的ip没有从iptables 中及时删除,通过 iptables -L -t nat | grep '20125' 来获取 iptables中转发给对应服务的规则,对比线上的 pod 列表后,发现 ip 列表一致。
本着 不行就重启 的简单法则,对边缘节点的 kube-proxy进行了重启,重启后发现问题依然存在。
通过此边缘节点测试了访问其它的服务,结果一切正常,没有问题,开始怀疑跟 服务本身的部分 pod 有关。
在一台 k8s 工具机上通过 kubectl 获取对应的 pod 列表, 然后访问服务,测试所有 pod 均正常。
#!/bin/bash
deployment="deployment-name"
ips=`kubectl get endpoints ${deployment} -o json| jq '.subsets[].addresses[].ip' | tr '"' ' ' | tr '\n' ' '`
curl_time='\ntime_namelookup: %{time_namelookup}s\n time_connect: %{time_connect}s\n time_appconnect: %{time_appconnect}s\n time_pretransfer: %{time_pretransfer}s\n time_redirect: %{time_redirect}s\n time_starttransfer: %{time_starttransfer}s\n'
for ip in $ips
do
echo $ip
curl -k -s -w $curl_time -i 'https://'${ip}'/status.html'
done
将获取到的 pod ip 列表写到上边脚本里,将脚本拷贝到有问题的边缘节点机器上,再进行尝试,结果发现到其中一个 pod 的服务不通。
此时能稳定复现了,开始抓包分析,抓包后发现,错误的情况为 SYN 不断重传,握手建立不起来。
查询了 pod 所在 node 上的其他服务的 pod ip,从边缘节点也访问不通。
从边缘节点 ping 了 pod 所在宿主机的 ip,发现 ping 的前几个有丢包,后边恢复正常, 再重新 ping 时,也正常了。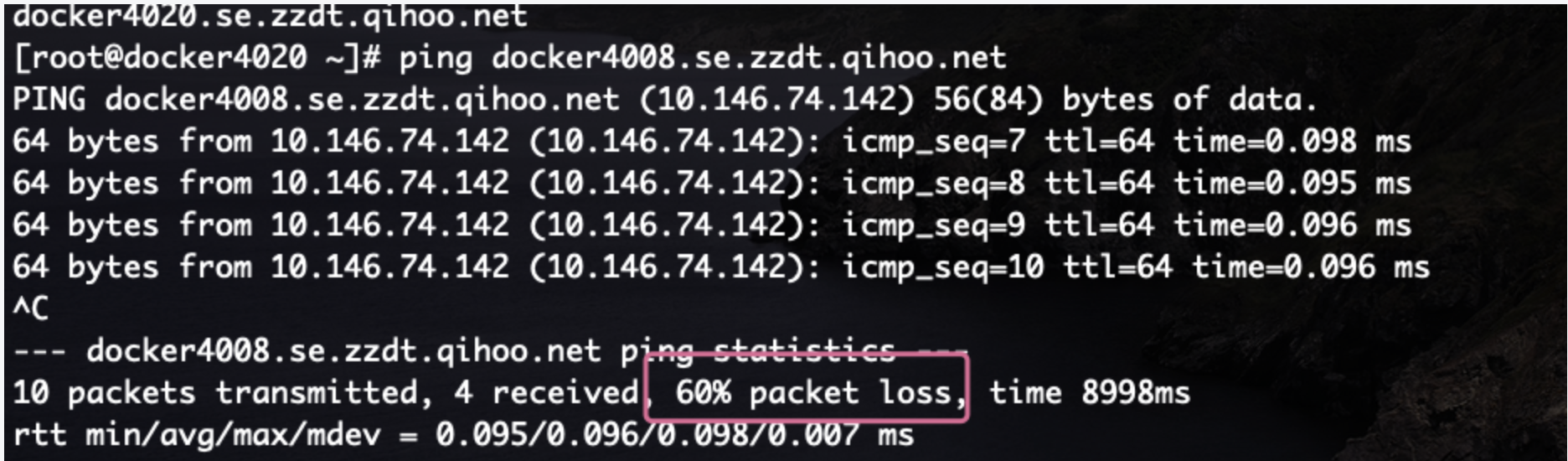 此时意外的发现,边缘节点 能正常访问 pod 了,以为是有人调整了网络上的一些配置。
此时意外的发现,边缘节点 能正常访问 pod 了,以为是有人调整了网络上的一些配置。
尝试了另外一台有问题的边缘节点,到 pod 也是不通, ping 开始有丢包,但是后边正常不丢包后,访问 pod 也能访问通了。
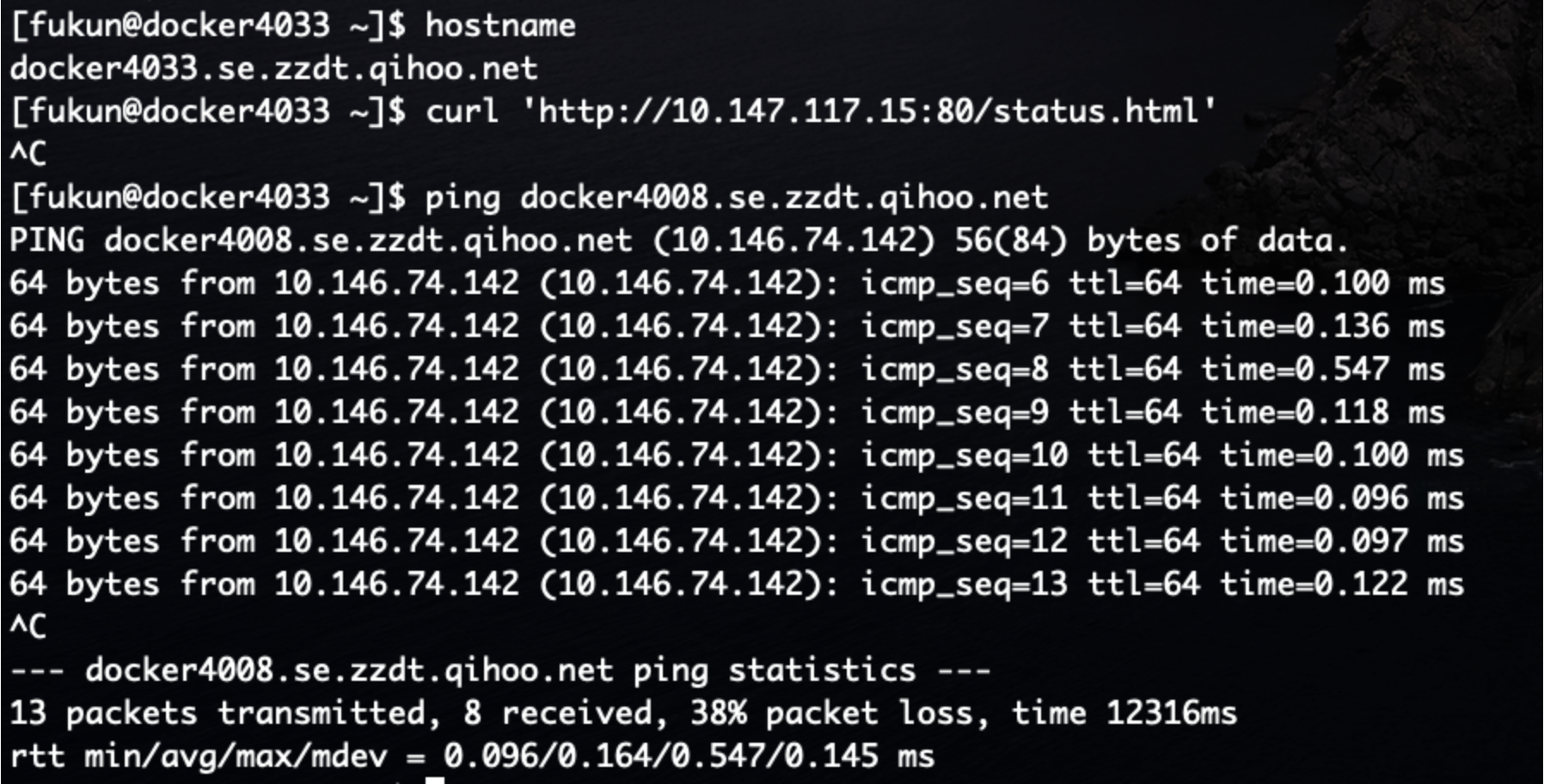 这个问题很奇怪,开始不通,ping 之后就正常了。
这个问题很奇怪,开始不通,ping 之后就正常了。
怀疑过 arp 有问题,但是看了下两台机器上对方的 arp 信息,都是正确的。(注:此时在恢复后的机器上查看的 arp 信息,还专门核对了 MAC 信息的准确性,错过了发现问题的一个良机)
在边缘节点 通过 traceroute 宿主机 ip 跟踪路由发现,只能到达网关地址,不能到达宿主机,这里就仅仅是两台物理机之间的网络问题了,开始请 网络组 同事介入。
在网络组同事的协助下,开始通过 ping 以及在交换机做策略进行问题的复现和排查,中间提到过 arp 的问题,查看了 边缘节点 上到目的宿主机的 arp 信息,是正确的(看了 node 节点上有边缘节点的 MAC 地址,但并未核实正确性)。
在各种调试中不断想办法定位,一直没有太大进展,由于 机器一旦 ping 之后就恢复正常,不能复现,所以需要不断的调整 源ip 和 目的 ip,网络组的同学提到,是否可以清下 arp 信息,然后再试,看能否复现。
清了 arp 后再 ping,居然复现了。
而且意外的发现,容器宿主机 前后两次取到的 边缘节点 机器的 MAC 地址,是不一样的。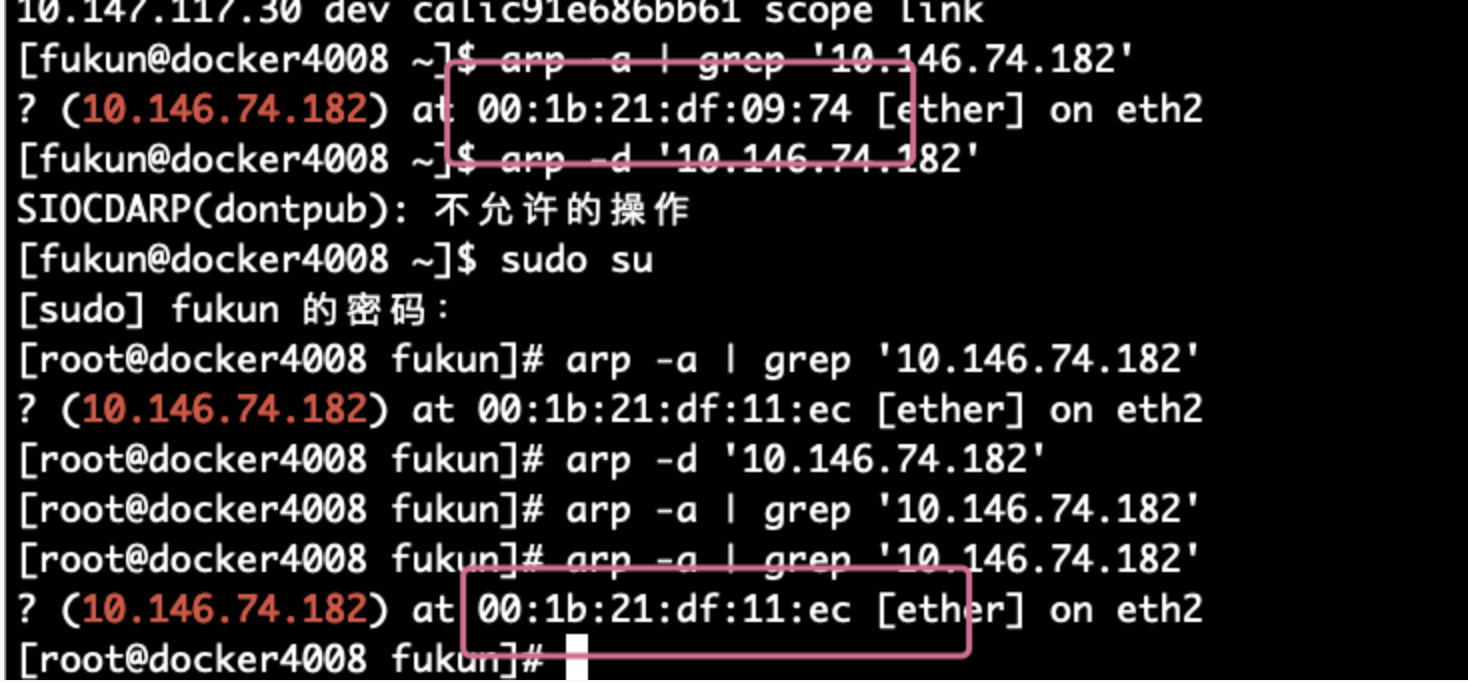 通过在 容器 宿主机上抓包,发现宿主机在寻找 边缘节点 ip 的 MAC 时,有多个回应,造成了一定几率上的 宿主机 拿到错误的 MAC 地址,从而无法向 边缘节点发送数据。
通过在 容器 宿主机上抓包,发现宿主机在寻找 边缘节点 ip 的 MAC 时,有多个回应,造成了一定几率上的 宿主机 拿到错误的 MAC 地址,从而无法向 边缘节点发送数据。
这也解释清楚了为什么边缘节点访问 pod 服务时,会不断的 SYN 重传,是由于 pod 宿主机找不到 边缘节点的正确地址,所以 返回的 ACK 丢失,边缘节点就不断进行重传。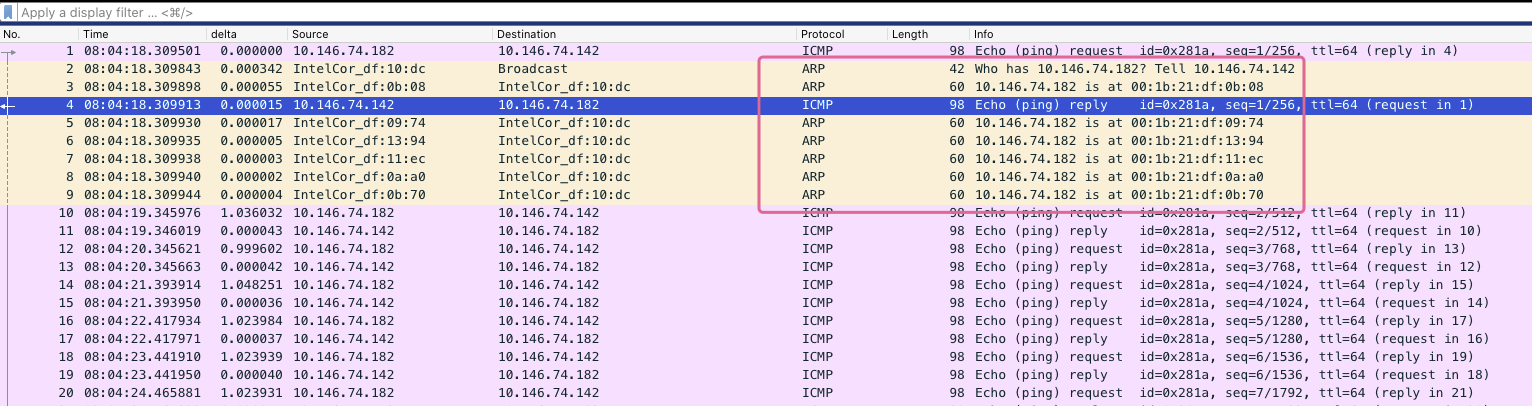
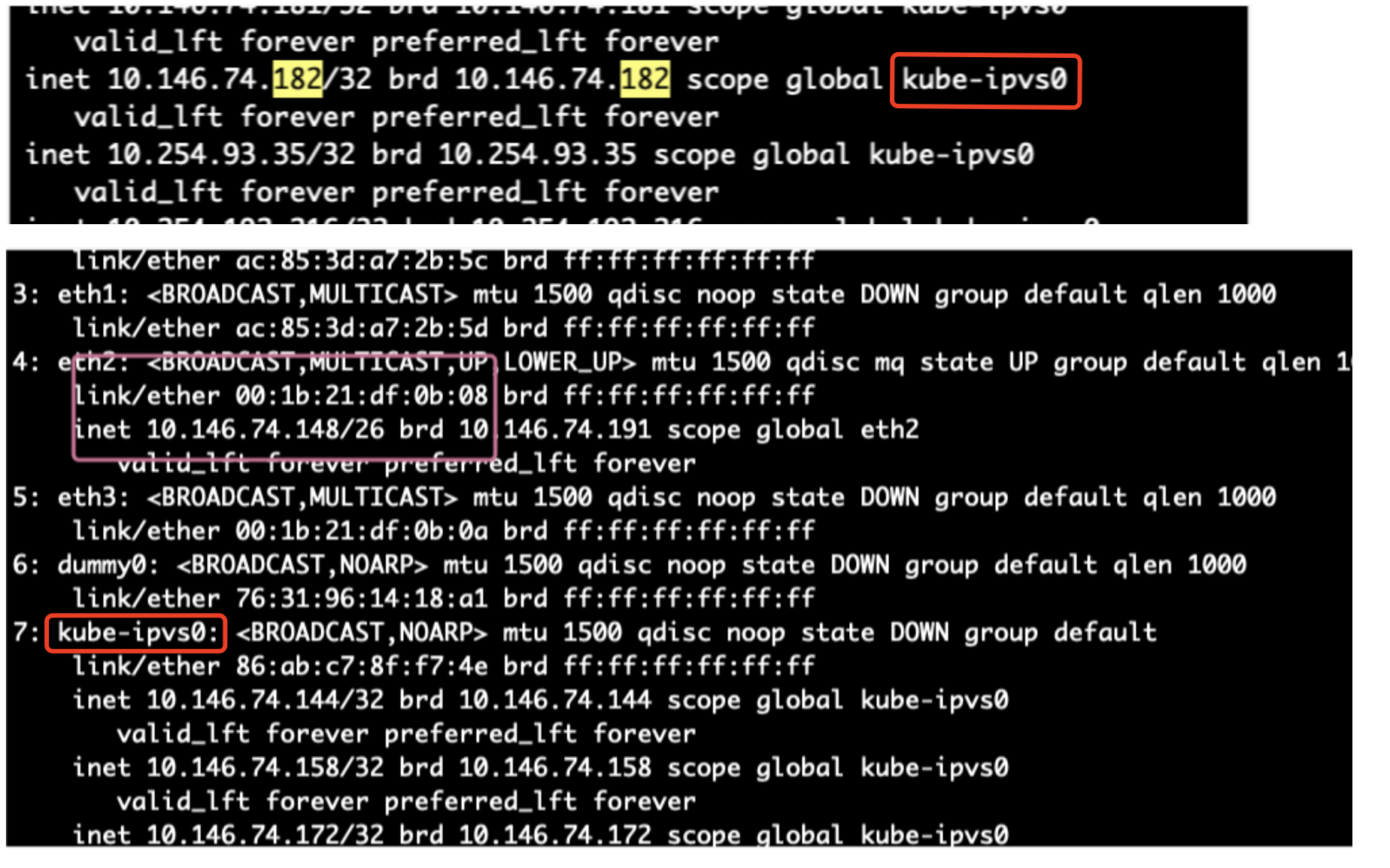
进一步查找这些 ARP 回应是哪来的,拿到 ARP 返回的 MAC 地址,到其他正常的机器上查看 ARP 表,发现 错误的几个 MAC 地址均来自于 k8s 集群内的 几台 ingress 机器。这批机器上启用了 ipvs 模式的 kube-proxy,把边缘节点的 ip 都绑定在了 kube-ipvs0 的虚拟网卡上。(猜测这批机器本来是打算使用 ipvs 模式的 Kube-proxy 来替换 iptables 模式的,不过可能由于某些问题没有实现,所以改用了 ingress,ipvs 的配置保留了下来)
在 ARP 询问 边缘节点的 IP 时,这些机器认为自己是 宿主机的 IP,做出了 ARP 的回应,回应的值为自己的 物理网卡 MAC 地址。
 使用
使用 systemctl stop kube-proxy 停掉 Kube-proxy, 并使用 ip link delete kube-ipvs0 删除 kube-ipvs0 的虚拟网卡。
再进行重试时,就没有问题了。
同时查看了其它集群对应的 ingress 机器,也同样部署了 ipvs 模式的 kube-proxy,为什么没有出现同样的情况呢,经过抓包 ARP 信息分析发现,其他机房的边缘节点机器都有两张网卡,arp 信息使用的其中一张网卡,kube-proxy 的 ipvs 绑定的是另外一张网卡,这样容器的宿主机在向边缘节点通信时,返回的 MAC 地址也只有一个,不会产生问题。
尚不清楚的问题:这个有问题的集群存在这种情况, 但为什么只有部分 node 出现问题?出现的问题的机器有的重启过,有的没有重启。重启过的机器 arp 表清空,需要重新学习,这个可以理解;其它一些机器并没有重启过,如果是 arp 过期导致的重新学习,那为什么更多的其他节点又是正常的?
目前大概定位到这块出问题的机器都部署在临近的机架上,可能是连接的相同的交换机,需要进一步分析。