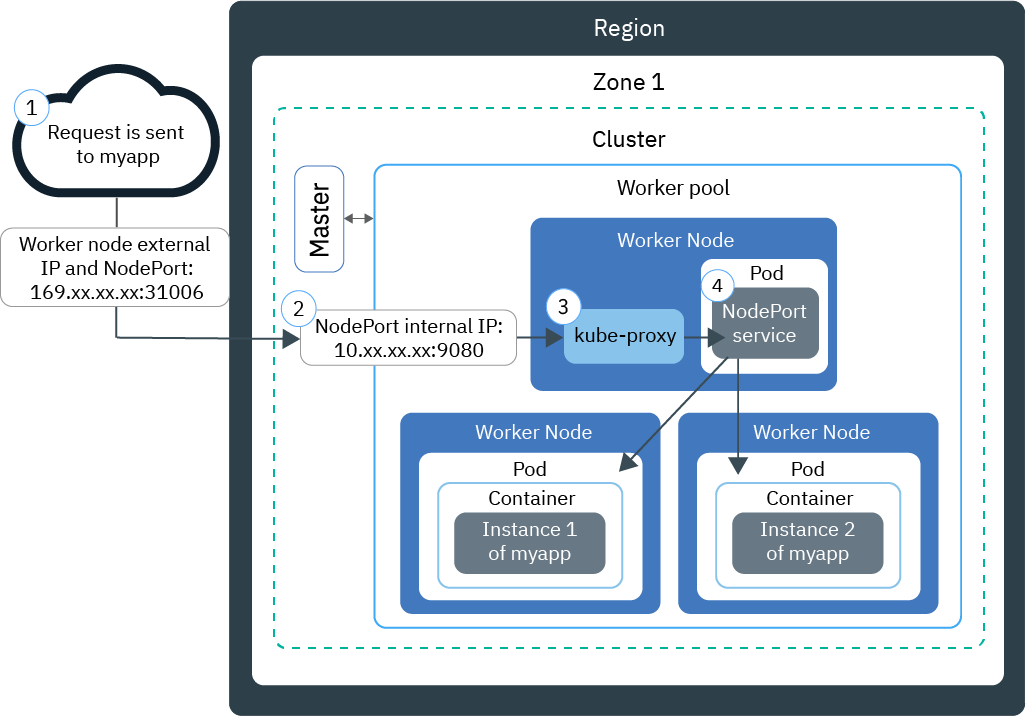
流量统计方法分类 – web server log 和 page tagging
一、什么是web server log 和 page tagging
**web server log:**使用软件将原始数据解析为有用的数据。主要的工具有awstats、webtrends(收费)。
以下为具体的服务器日志:
202.80.215.14 - - [10/Mar/2012:01:29:59 -0700] "GET www.domain.com/index.php HTTP/1.1" 200 99314 "-" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.1.249.1045 Safari/532.5"web server log主要可统计到的数据为:

Apache日志包含的各字段内容及其含义
**page tagging:**使用JS代码将页面统计数据发给服务器。典型的代表为Google Analytics,百度统计,51la, CNZZ,量子统计,Ominture…
以Google Analytics为例,以下为Google手机的代码:
http://www.google-analytics.com/__utm.gif?utmwv=4.8.9&utmn=444576131&utmhn=www.douban.com&utmcs=utf-8&utmsr=1280×768&utmsc=32-bit&utmul=zh-cn&utmje=1&utmfl=10.2%20r152&utmdt=%E8%B1%86%E7%93%A3&utmhid=974895699&utmr=-&utmp=%2F&utmac=UA-7019765-1&utmcc=__utma%3D30149280.845782037.1298725704.1298782111.1299505037.3%3B%2B__utmz%3D30149280.1298725704.1.1.utmcsr%3D(direct)%7Cutmccn%3D(direct)%7Cutmcmd%3D(none)%3B&utmu=qBMPage Tagging=服务器日志(部分)+客户端信息+自定义信息
其强大之处是可以收集包括:浏览器数据+操作系统数据+用户数据(SessionID,UserID)+转化数据+自定义标签
二、web server log 和 page tagging 的比较
Web Server Logs优点:
- 不需要在页面中加代码,服务器会自动记录log files
- Log files包含搜索引擎爬虫的访问数据,有利于提供SEO数据
- 可以多域名的日志放在一起分析,可以跨域。
- 真实记录所有访问,而Page Tagging无法真实记录所有访问
Web Server Logs缺点:
- 使用比较麻烦,每次要分析日志,配置web服务器以输出合适的日志。
- 搜集的客户端信息不如Page Tagging丰富,例如flash版本,是否安装java之类从日志是看不出来的
- 日志的存储管理也是挺头痛的事,尤其是当每天都产生几十G日志的时候
- 使用CDN时,需要合并日志分析。
page tagging优点:
- 只要打开页面就会记录,即使从缓存中读取页面内容。
- 搜集到一些通过日志不能搜集到的客户端信息。
- 可以记录更多的用户活动和信息,比如鼠标点击、页面停留时间等。
- 通过Cookie识别访问者,比依靠IP识别要更准确。
page tagging缺点:
- 当客户端禁止JS或禁止Cookie时,都会影响统计结果。
- 存在一定误差,把代码加在页面代码尾部会导致没有执行到。
- 不能统计用户对图像,视频,音频等文件的访问,这些文件不能插入统计代码。
- 不能统计带宽信息。
- 需要在页面中加代码,如果切换统计服务提供商的话,需要大批量更新代码。
除此上面page tagging的缺点以外,page tagging 还需要注意的一些问题:
1、垃圾回收与Image对象
大部分的日志收集JS请求都是使用Image对象来请求的(google,baidu,Omniture等)。目前有两种方式来使用JS的Image对象,一个是document.write,这种方式将这个Image对象挂到DOM树上,这种情况下会影响整个页面的渲染,Window.Onload函数就是在所有的DOM树都渲染完成后才执行的。第二种方式是直接new一个JS的Image对象,这个JS变量就是一个独立的对象,在某些情况下会被JS的垃圾回收机制回收掉,这个概率很小,也可以采用方法来避免。
2、线程与JS执行顺序
在javascript中是没有线程机制的,JavaScript引擎是单线程运行的,(在IE的一个窗口内,Firefox的一个Tab内,Javascript是单线程运行的)浏览器无论在什么时候都只且只有一个线程在运行JavaScript程序。在JavaScript引擎运行脚本期间,浏览器渲染线程都是处于挂起状态的,也就是说被”冻结”了。JavaScript脚本的执行不影响html元素事件的触发。
正常情况下JS代码都是从上到下执行的,如果有引入的JS文件,会先执行JS文件,JS中如果有document.write指令,会将内容输出到当前执行的页面位置的下面(如果有JS代码会在下一个JS解析过程中继续执行)。具体在处理过程中各个浏览器略有差异,但是基本的原理不变。在这个过程中如果碰到JS代码错误,会跳过本段JS继续执行。在这种情况下,直接的Apache日志和JS日志就有一个时间差,在页面的URL请求后过一段时间才执行JS请求。这样数据就会有一部分差距。这部分的差距根据不同的地区、用户有差别。
最后,两种方式没有谁好谁坏,只要能满足需求就是最完美的。
参考链接:
http://www.biaodianfu.com/web-server-log-and-page-tagging.html