熟悉 k8s 的同学都会知道,Kubernetes 的网络定义了一套容器网络 API 接口 CNI(Container Network Interface),这样我们就可以使用任意的第三方网络插件,给我们提供了多样化的网络解决方案。每个解决方案,都有自己的实现方式,相应的,当出现一些网络问题时,也需要我们有能力去分析定位和解决问题。
先介绍一下我们大概的业务背景:
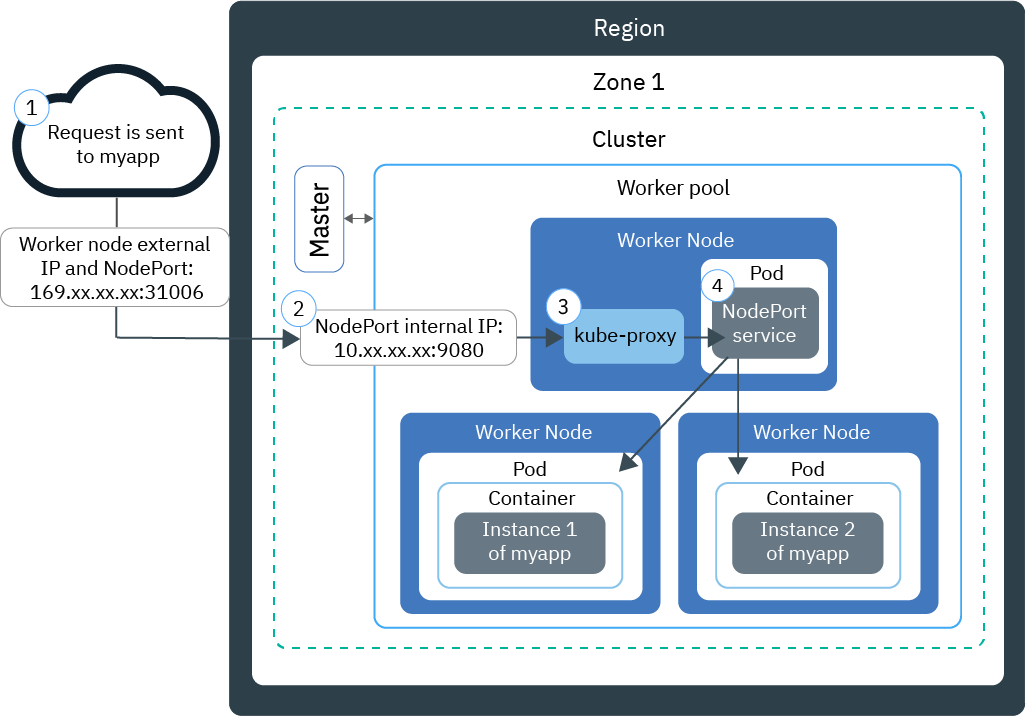
我们的服务部署在 360 搜索自建的 k8s 云平台上,有 4 个主力集群,业务对外提供 service 的方式为 基于 iptables 模式的 kube-proxy, 通过 nodePort 的方式,指定多台 external IP (也称为边缘节点),前边挂载 lvs 的形式。
从网上找了个图,比较类似了,只是把左边的 Worker node 多部署几台,前边通过 lvs 实现负载均衡即可。
在某次业务问题排查中,定位到通过某个集群的 lvs vip 访问业务时,有一定的几率产生超时,于是就有了此次的踩坑之旅。
先用一个脚本查看访问 vip 的超时情况,发现是链接阶段超时:
TIME_OUT_FMT='\ntime_namelookup: %{time_namelookup}s\n time_connect: %{time_connect}s\n time_appconnect: %{time_appconnect}s\n time_pretransfer: %{time_pretransfer}s\n time_redirect: %{time_redirect}s\n time_starttransfer: %{time_starttransfer}s\n'
for n in {1..20} ;
do
echo $n;
# 这里 url 用业务的 vip 地址
curl -w "$TIME_OUT_FMT" -o /dev/null -s 'https://fukun.org'
done
根据之前另外一个集群的经验,怀疑是边缘节点容量不足导致的,但是查看边缘节点的网卡丢包情况,并未出现异常,不过还是先对此集群的边缘节点进行了扩容,但扩容之后并没有好转。
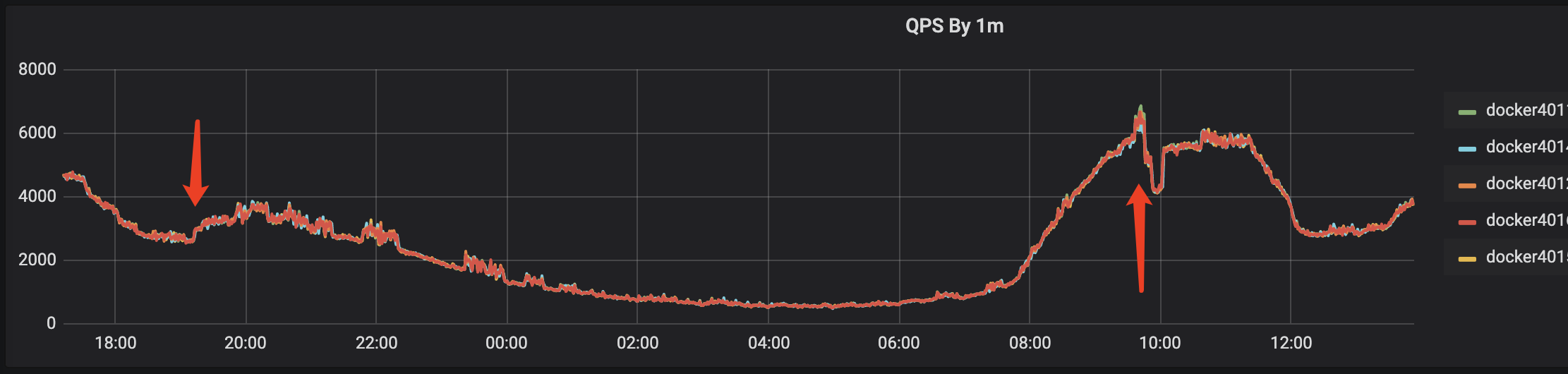
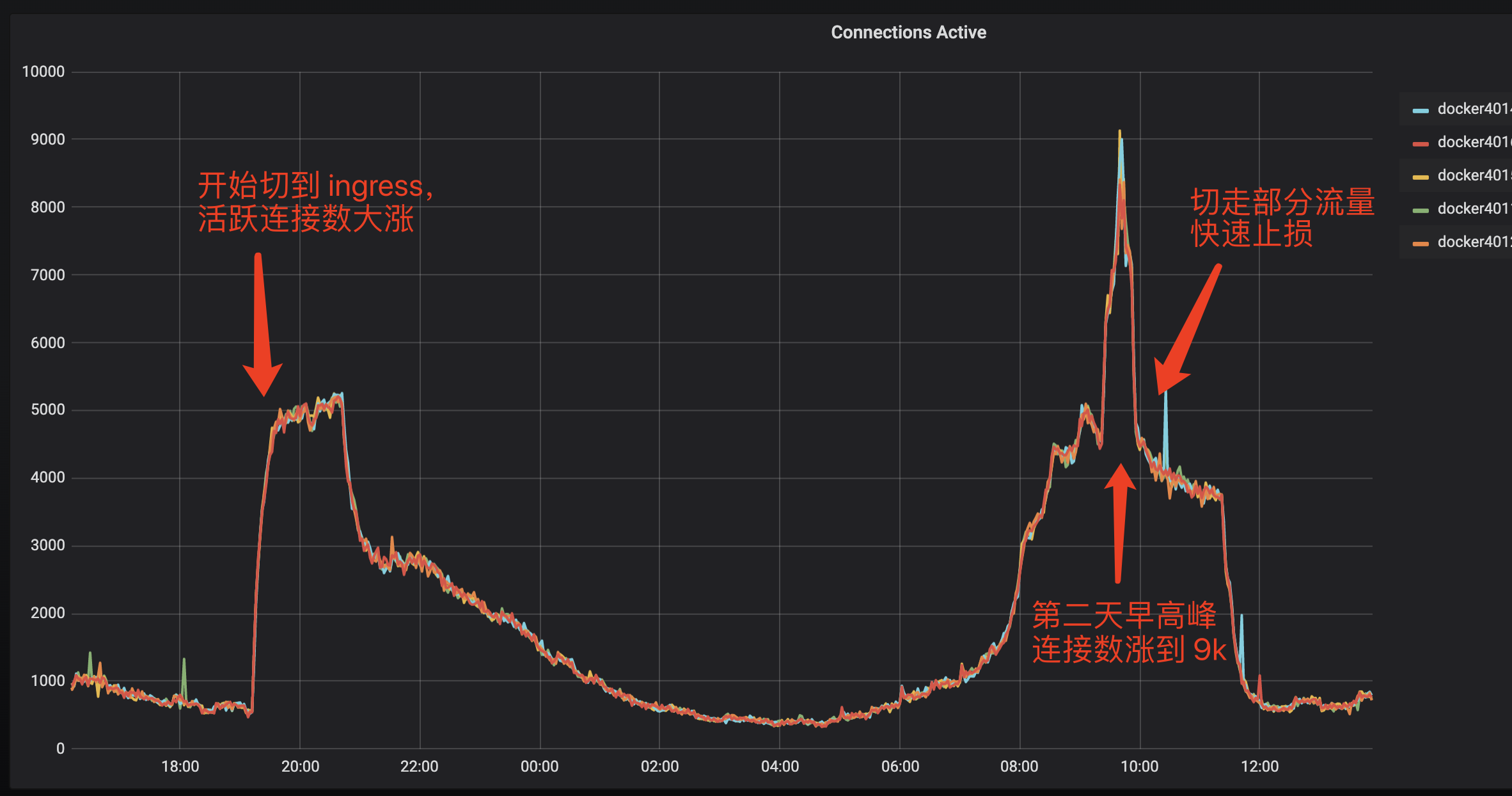
此时由于对业务任然在产生影响,为了止损,所以快速的通过 ingress-nginx 部署了一个直接对外的支持 HTTPS 的服务,切换到 ingress 后,业务检测正常,此时是下午6、7点钟,已经不是流量高峰,当到第二天流量早高峰时,由于 ingress 服务之前主要是内部业务之间调用,并未启用 HTTPS,虽然单机的 QPS 6800+ 相比之前的 6000+ 并没有增加多少,但是 nginx 活跃连接数却从之前的单机 700 飙升到了单机 8000, 此时 ingress 服务虽然还能用,但对延迟已经有影响了,对于内部大部分 100ms 级别的请求来说,超时的影响已经比较严重了。所以此时只好先快速的把流量切到其他机房,避免 ingress 影响扩大。