在大型互联网站的数据库部署中,部署最多的数据库为MySQL。随着MySQL中Innodb存储引擎对事物的支持,MySQL在互联网公司部署中,应用量越来越多。典型应用MySQL的公司有Google、Taobao、Baidu等大型互联网公司。MySQL的优势在于其高扩展性和价格优势等。实际上,MySQL可以免费应用于企业级的部署中。
在MySQL复制方式部署中,有两种部署方式:同步复制和异步复制。同步复制采用NDB存储引擎,异步复制需要使用mysql-proxy结合master-slave实现。
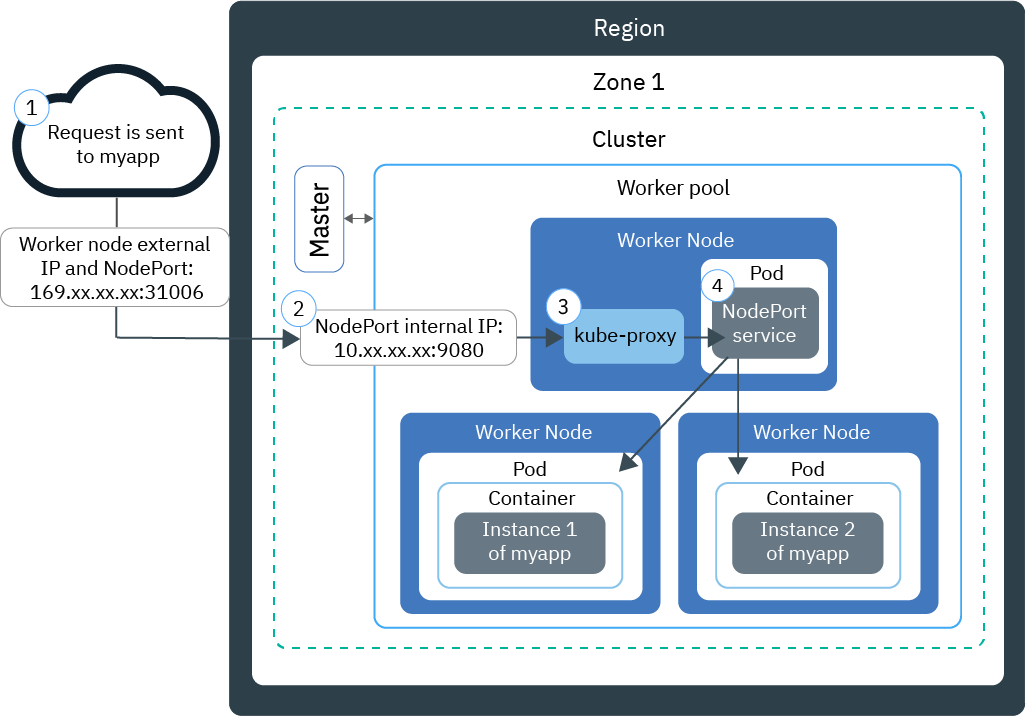
mysql-proxy是一个MySQL的代理服务器,用户的请求先发向mysql-proxy,然后mysql-proxy对用户的数据包进行分析,从下一层的mysql 数据库中选择一台数据库,将用户的请求包交给mysql处理。
首先MySQL Proxy 以服务器的身份接受客户端的请求,根据相应配置对这些请求进行分析处理,然后以客户端的身份转发给相应的后端数据库服务器,再接受服务器的信息,然后返回给客户端。所以MySQL Proxy需要同时实现客户端和服务器的协议。由于要对客户端发送过来的SQL语句进行分析,还需要包含一个SQL解析器。MySQL Proxy通过使用lua脚本,来实现复杂的连接控制和过滤,从而实现读写分离和负载平衡。所以部署MySQL-Proxy需要安装运行Lua语言的环境。典型的MySQL-Proxy应用为实现读写分离。
异步复制主要为了解决读写分离的问题。因为用户对网站的访问有读操作多,写操作少的特点。甚至像taobao.com这样的网站读写比例高达10:1,所以采用MySQL-Proxy结合主从异步复制实现读写分离是非常重要的增快访问速度的方法。这样如果有更高的用户访问需求,通过增加slave机器,不会对现有系统提供的服务产生影响而实现很好的、很灵活的业务扩展。
阅读全文